Scale Development with Noncognitive Items
An Introduction
Learning Goals
- Overview of the different skills and expertise needed to design survey scales
- Understand the cognitive processes involved when responding to a scale question
- Learn how to design and test a non-cognitive scale
Scale Design Jargon
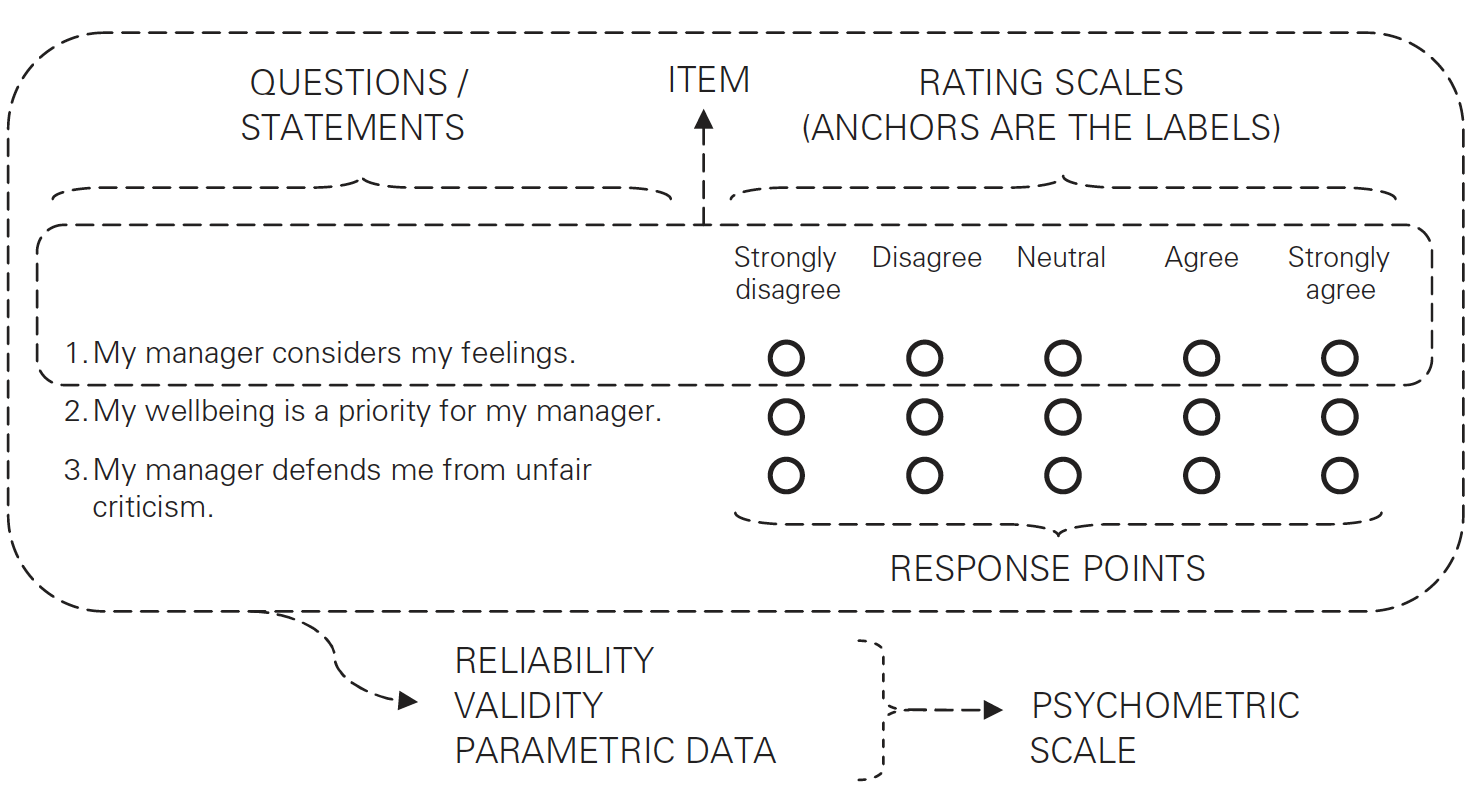
Robinson (2018). Using multi-item psychometric scales for research and practice in human resource management
Scale Design Jargon
- Construct: An attribute or idea that not directly observable (or measurable)–a concept.
- Questions / Statements: The stimuli that generate a response from a respondent.
- Response Points: A circle or check-box in which respondents indicate their response.
- Response Labels: A label that accompanies a response point that clarifies the meaning of a response point (e.g. strongly agree).
- Response / Rating Scales: The measure along which respondents respond to a question or statement.
- Items: A combination of a question or statement and a rating scale.
- Scale: A set of closed-response items (preferably three or more) that are designed to measure the same underlying construct.
- Questionnaire / Survey: A set of two or more scales.
The Required Skills and Expertise
- Designing and testing a scale or large-scale survey requires a diverse set of of skills and expertise:
- Statistics: Focused on adequately sampling the focal population and incorporating the sampling design into subsequent analyses.
- Cognitive Science: Focused on understanding the cognitive processes involved in question response to predict, explain, and reduce response errors and biases.
- Psychometrics: Focused on evaluating the reliability (response consistency) and validity of each individual scale.
Cognitive Science and Scale Design
Cognitive Process Model of Question Response
Originally developed by Roger Tourangeau (1984), the Cognitive Process Model of Question Response posits that a respondent engages in four distinct cognitive processes when responding to a question:
- Comprehension: Work to understand what the question / statement is asking of you.
- Information Retrieval: Recall relevant information from long-term memory.
- Judgment & Estimation: Combining or supplementing the information you’ve retrieved into an answer.
- Reporting an Answer: Mapping your answer to the question’s response options and altering the answer for consistency with prior answers, perceived acceptability, or other criteria.
Think Aloud Using Example Items
Here are two items (question + response scale) to help us think through the cognitive processes involved in responding to a question or statement:
My mentor treats me with respect. (Strongly Disagree to Strongly Agree)
Senior administrators at UGA show that they care about the university employees. (Never to All the Time)
Do you think they are well designed items?
Response Strategies: Optimizing or Satisficing
- Optimizing and Satisficing make up the two ends of a continuum that describes how thoroughly a respondent engages in the information retrieval and integration needed to a question response.
- Optimizing: Effortful engagement in Comprehension, Retrieval, Judgement & Estimation, and Reporting
- Satisficing: Providing a response that is “good enough.”
- Weak Satisficing: Less effortful engagement in Comprehension, Retrieval, Judgment & Estimation, and Reporting
- Strong Satisficing: Skipping the Retrieval and Judgment & Estimation processes all together.
- As scales (or surveys) get longer or harder, a respondent’s motivation to accurately respond declines and they may start to take cognitive shortcuts to question response.
Errors and Biases in Question Response
- Errors can occur during any of the cognitive processes:
- Misinterpret the question (comprehension error)
- Forgetting and other memory problems (retrieval error)
- Flawed judgment or estimation strategies (judgment & estimation error)
- Biases can occur–especially when satisficing:
- Item non-response
- No Opinion / Middle Response Inflation
- Acquiescence Bias
A Scale Development Workflow
- Design the scale
- Create a measurement framework
- Write a lot of questions
- Write a response scale that matched your questions
- Evaluate your initial items
- Pilot test the scale (or survey)
- Select a representative respondent sample
- Allow respondents to give feedback about the items
- Evaluate the quality of the scale(s)
- Remove poorly fitting items
Elements of Scale Design
Responding to Items is Tiring
“Survey respondents are often asked to expend a great deal of cognitive effort for little or no apparent reward.”
Krosnick, 1991
Remember the Respondent!
Survey fatigue is real!
All of our scale design choices should strike a balance between scientific rigor and helping out the respondent.
Building a Measurement Framework
- For each scale being developed, a measurement framework:
- Lists the goals of that scale (research questions / hypotheses it will test)
- Provides a definition of the construct being measured by the scale
- Hypothesizes how the focal construct is related to other established constructs
Designing Questions
Writing questions is easy. Writing good questions is hard! There are four important dimensions to writing a good question:
- Relevance
- Audience
- Language
- Structure
Question Design: Relevance
Questions should be relevant to the construct they are designed to measure.
Use the construct definition in your measurement framework to help generate questions.
Do not repeat questions, you need multiple distinct questions per scale.
Your question should measure one and only one construct.
Keep items and words within an item relevant. Use only words that your respondents will understand and are relevant to the study context.
Question Design: Audience
Know your target respondents, and tailor the questions to them.
Consider the respondents’ cognitive skills when writing questions (are they adults or children?)
Consider if respondents will have sufficient information to accurately respond to the question
Consider if respondents can accurately recall the information needed to answer the question
Consider the diversity of your respondents (multicultural, non-bias questions)
Question Design: Language
Use clear and simple language that is familiar to the respondents.
Use simple and familiar words
Use objective, non-leading phrases (stay away from emotion-laden words)
Use concrete and precise language
Write questions at a middle school reading level when possible
Question Design: Structure
Questions should be structured as brief, simple sentences (subject, verb, complete thought).
Keep questions to 20 words or less with no more than three commas
Use complete sentences
Questions should present only a single idea—no conjunctions
Avoid negative phrases if possible
Designing Response Scales
There are three important dimensions to writing a good response scale:
- Response Scale Length
- Response Scale Labels
- Neutral and Opt-Out Options
Response Scale Design: Length
Response scales should have between five and seven response points.
Survey data collected using five to seven response points can be treated as continuous
Reliability levels off between five and seven response points
Consider how well respondents can discriminate among different response points
Response Scale Design: Labels
You should label every response point with a distinct label.
Label should be consistent with the question / statement
The two endpoint labels should be opposites (Strongly Disagree and Strongly Agree)
Labels should be equal intervals along a continuum (Strongly Disagree, Disagree, Agree, Strongly Agree)
Labels should be ordered from negative (Disagree) to positive (Agree)
Response Scale Design: Neutral and Do Not Know Options
Avoid using response options that make it difficult to distinguish between respondents who hold different opinions, judgments, or attitudes.
Use an even number of response points (6 points)
Only use a “Do Not Know” option if you believe uninformed respondents might provide inaccurate responses
Visually separate the “Do Not Know” option from the rest of the response scale
Evaluating your Preliminary Items
Before piloting your items, it is important to subject them to a content analysis or expert review:
- Content Adequacy
- Subject Matter Expert Review
- Psychometric Review
- Translator Review
- Editorial Review
- Bias Review
Content Adequacy
Content Adequacy1 is an analysis that informs you as to how well your questions correspond to the construct they were designed to measure—it is similar to content validity. Colquitt et al. demonstrate how to expand this analysis to the scale level.2
Have a sample of individuals (\(N \geq 50\)) rate the extent to which a question corresponds to the definition of the construct it is measuring (1 = Not at all to 5 = Completely). These ratings are referred to as the definitional correspondence ratings.
Have that same sample rate the extent to which a question corresponds to a definition of a different, but related construct—an orbiting construct. These ratings are referred to as the orbital correspondence ratings.
Use an ANOVA to compare the definitional correspondence ratings to the orbital correspondence ratings and retain only those items which have statistically higher average definitional correspondence values compared to the average orbital correspondence ratings.
Piloting your Scale
Selecting your Pilot Sample
Target Population: The population of inferential interest.
Sample Frame: A list of units that make up the population.
Sample: A randomly drawn set of units from the sampling frame.
\(\text{Sample Size} \approx\max(300, 10\times\text{number of questions})\)
What to Include in your Pilot Survey
- The set of scales you are developing
- Additional established scales that can be used to validate your scales
- Criterion-related validity evidence
- Convergent & Discriminant validity evidence
- Questions to gather respondent demographics
Gathering Item Feedback
For each item, you will want to know if respondents had any difficulty responding to the question or using the response scale. There are two ways to gather this information:
Think-alouds: Gather a sub-sample of respondents and have them talk through their thought processes as they respond to each question.
Closed-Response Questions about Item Quality: For each question, ask the respondent if they had any difficulty understanding what the question was asking or if the response scale was difficult to use.
Investigating Item and Scale Descriptives
Item Response Distributions: Are respondents using the full response scale?
Item and Scale means: Are responses inflated or deflated?
Item and Scale variability: Are responses clumped together?
Corrected Item-Total Correlations: How correlated is the item with a sum score that consists of every other item in the scale?
Inter-item and inter-scale correlations: Are certain items / scales too related or not related enough?
Evaluating Reliability
Reliability can be thought of as an index of how much of the observed variance in your scale is due to true variation on the focal construct.
- We can never actually calculate scale reliability, but we can estimate it:
- Coefficients of Internal Consistency: Coefficient alpha
- Coefficients of Stability: Test-Retest Correlation
- Coefficients of Equivalence: Alternate Forms Correlation
Coefficient Alpha
Coefficient Alpha is easily the most used and reported on reliability estimate.
Alpha ranges between 0 and 1 and you typically want values greater than .80
For each scale and item in a scale, you will want to calculate alpha-if-item-deleted values
Building your Validity Argument
“Validity refers to the degree to which evidence and theory support the interpretation of test scores for proposed uses of test.”1
- There are several types of validity evidence you can use to make the argument that inferences made from your scales are valid:
- Evidence Based on Test Content
- Evidence Based on Response Process
- Evidence Based on Internal Structure
- Evidence Based on Relations to Other Variables
- Evidence for Validity and Consequences of Testing
Finalize Your Scale and Repeat!
Remove or change items based on the information you gathered from the pilot sample
Give out the revised scales (survey) to a new sample (or a holdout sample from your original sample) and repeat the same analyses.
Document all of your work in a test manual!